Data is the driving force behind all our machine learning models. Although the word data itself buzzes a lot, the craft of getting and leveraging data for building conversational AI is unknown to many. A simple yet governing credo here at PolyAI is “no good data, no conversational AI” — which is also where our culture of data obsession comes from. At PolyAI, we put as much effort in creating cutting-edge conversational systems as in mastering dialogue data collection, because we know that a good AI system never comes for free. In fact, most chatbots and intelligent virtual assistants suffer from the chicken and egg problem — the system (chicken) and the data (egg) depend on each other, and therefore it is really hard to build conversational AI from scratch. In this post, we will take a short break from optimizing neural networks on our journey of forging conversational assistants and I will share with you the most popular data collection strategies from the research world. I will then follow up with how they are put into action at PolyAI to deal with what seems like a catch-22 paradox in our mission to build intelligent conversational systems.
Data first — models (and serenity) later
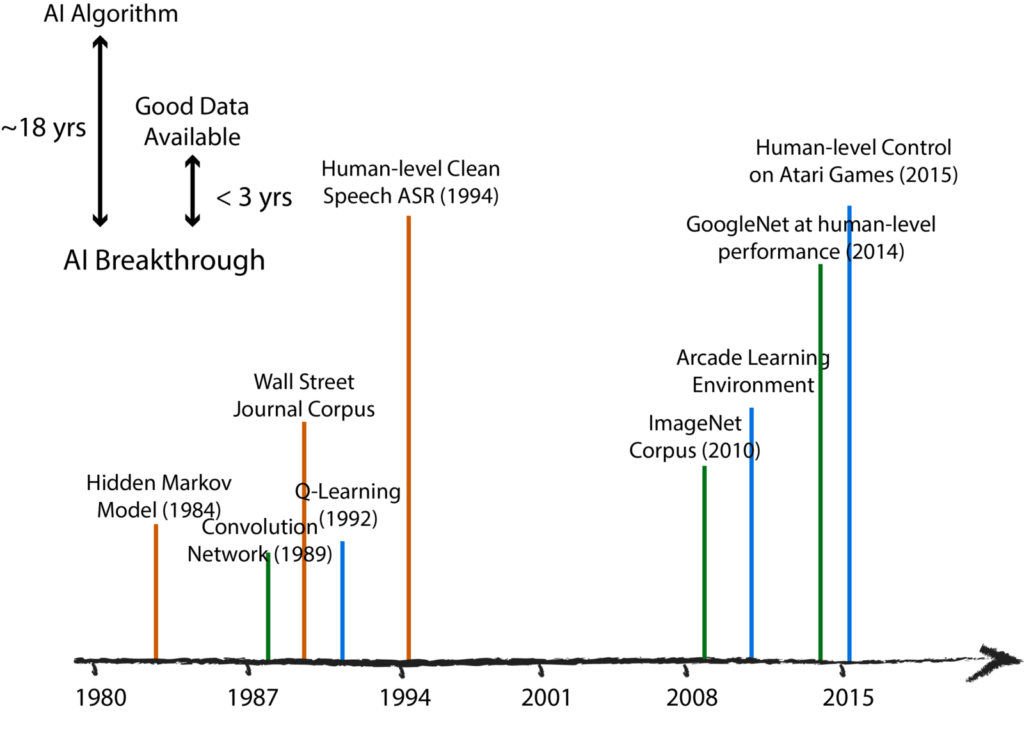
The significance of data is exemplified by a diagram that shows major AI milestones in three key applications across the last decades. This historical evidence elucidates that the data might actually be the key factor leading the progress in AI and machine learning. Behind human-level performance in speech recognition or computer vision, there are always challenging datasets supporting the research and encompassing enough information about the problems one is trying to solve. For instance, it took 23 years after the introduction of Q-Learning to witness a system based on reinforcement learning beating human in virtual ping-pong. However, this feat happened only 3 years after the Arcade learning environment allowed for easy interactions with the game, and we can see similar trends when it comes to convolutional neural networks and ImageNet. While powerful machine learning models are indeed required to unravel all the information stored in the data, there are simply no successful AI applications without having good, relevant, and challenging data to start from.
Why is collecting data for dialogue so difficult?
The diagram, however, doesn’t show any examples related to conversational AI, and this is not accidental. We are still waiting for the dialogue’s ImageNet moment: a huge and consistently annotated data resource that will really push our modeling efforts in conversational AI to new heights. Unlike object recognition in computer vision or automatic speech recognition, statistical dialogue modeling is a very ambiguous and not well-defined problem simply because it lacks consistent annotations and universal well-defined metrics. Annotations in dialogue datasets are therefore also extremely complex. The dialogue agent faces a variety of challenges while interacting with real users. For instance, the coverage of the conversation is practically infinite as humans can refer to out-of-domain concepts, use metaphors, or rely on the interlocutors’ commonsense or general knowledge. The conversation requires both sides to be active across many turns, and it relies on context: concepts introduced at the beginning of a conversation can be referred to much later. Finally, conversations are also grounded in the real world where visual or audio clues also serve as an integral conversational context. It goes without saying that dialogue systems cannot deal with these levels of complexity without any experience, that is, without seeing and referring to something similar in the data first.
The magic triangle of conversational AI data collection
In academic research, there are three main approaches to data collection for conversational AI. They can be roughly grouped into three informally named categories: 1) machine-to-machine, 2) human-to-machine, and 3) human-to-human.
1.Human-to-Human (H2H). The most intuitive strategy to build a powerful conversational system is to directly mimic human behavior by learning from large amounts of real human-to-human conversations. In theory, every message board could be seen as a potential source of a learning signal. But in reality, such models perform poorly on specific tasks, and the reintroduction of domain-specific datasets makes us face the chicken-and-egg dilemma again. The so-called Wizard-of-Oz (WOZ) data collection paradigm comes to the rescue here. In the WOZ paradigm, a human (e.g., a crowdworker) takes the role of a user with a specific task in mind: for instance, she wants to book a restaurant through a call center, or has a question for a customer service. The role of the system agent is then played by another crowdworker who has access to the knowledge (e.g., databases, FAQs, the user’s history) required to complete the task. An actual conversation is set within a particular domain and “mocked” between the two parties.
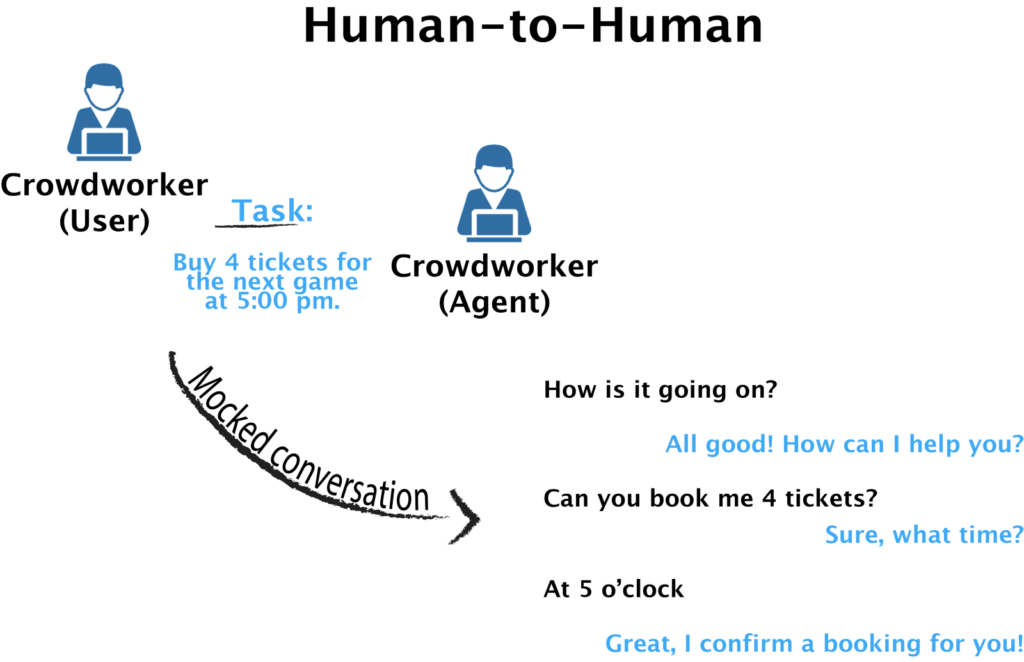
While the WOZ approach does produce datasets that can be seen as a good approximation to real-world conversations, its main downside is its low portability: customizing UI for each task and cleaning noisy annotations is (too) time-consuming. Nonetheless, the WOZ paradigm is very popular in academia, and it has been used to create two largest research datasets for task-oriented dialogue today: Stanford multi-domain dataset (SMD) and Multi-Domain Wizard-of-Oz (MultiWOZ).
2. Human-to-Machine (H2M). The most popular data collection approach among “intelligent” virtual assistants on the market nowadays is the Human-to-Machine approach, based on bootstrapping. The idea is to launch an initial system which interacts with the real users. Chatting with humans means collecting real data, and the system can be improved afterwards by analyzing conversation logs. This methodology fits quite well with the build-measure-learn software development cycle advocated by the lean startup movement. For this reason, it is the go-to data collection framework for the majority of bot building platforms.
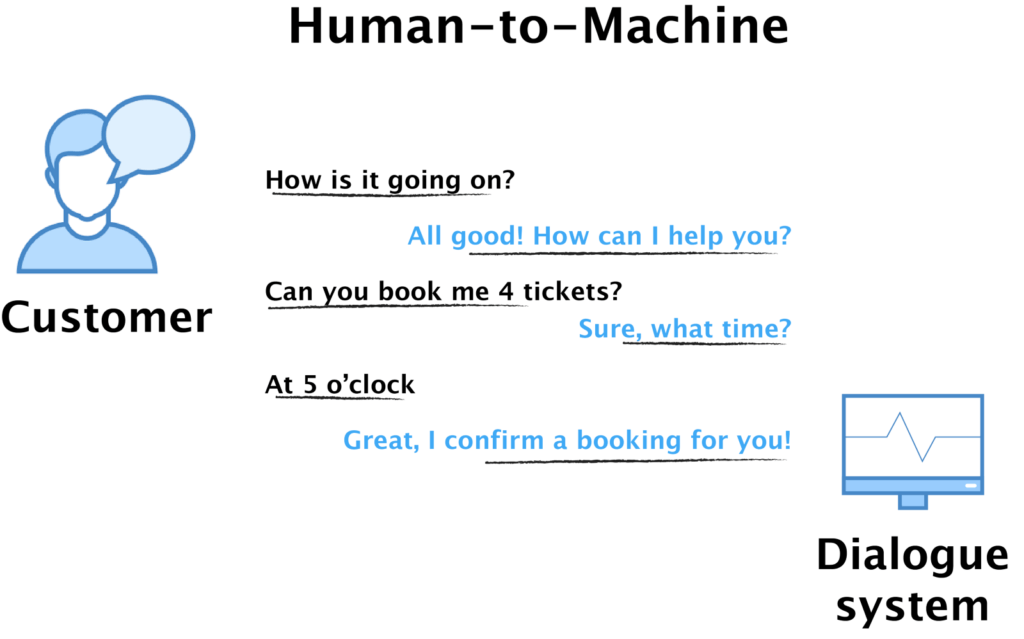
However, there is a caveat with H2M — it needs a working system to start collecting the data. Not to mention that we face the chicken-and-egg problem all over again. Even worse, the data quality is now heavily restricted by the (in)capabilities of the initial system. A limited system will prompt the users to adapt to simpler input examples or use unnatural responses. Consequently, you will end up collecting data that is tailored to your system, and not the data you want your system to model. Despite its limitations, the H2M approach can probably still produce the best real data if the process is executed correctly. The following two dialogue datasets are probably the most well-known research datasets generated by the H2M approach: Let’s Go dataset and Dialogue State Tracking Challenge 2.
3. Machine-to-Machine (M2M). The third data collection paradigm, Machine-to-Machine, focuses on collecting various language expressions for building better individual components of the conversational agent related to natural language understanding and generation — this is usually done by employing an artificial simulated user to interact with the system in a controlled environment. In theory, this paradigm can create an infinite number of conversations to cover all possible in-domain dialogue flows. These simulated dialogue paths, which come in the form of dialogue templates, are then “translated” to natural language by crowdworkers. Following this process, we avoid the challenge of labeling ambiguous semantics present with the previous two paradigms by simply asking the crowdworkers to generate sentences from the simulated labels.
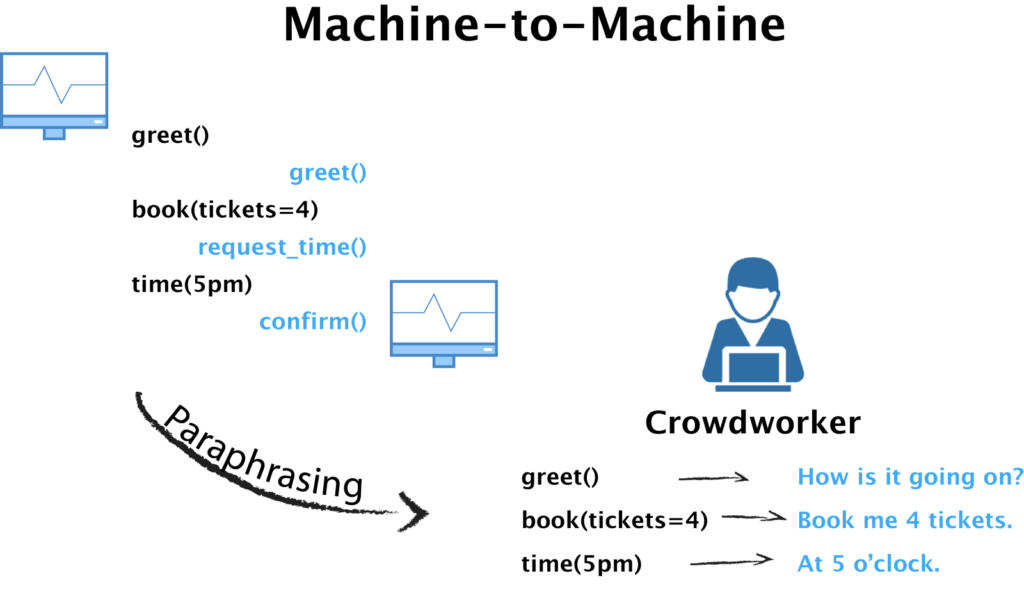
The major downside, however, is that all conversations are engineered and any unseen event (e.g., unforeseen flows, repetitions, misunderstandings) will break the system very easily. This eventually harms the user’s satisfaction with the system. Furthermore, creating a good user simulator is the craft on its own and it’s really hard to make it right to begin with. Two publicly available software packages based on the M2M paradigm were introduced recently — ParlAI and PyDial. If you want to find out how to generate natural language from simulated dialogue templates, take a peek at the M2M dataset.
Conversational AI development and Data Collection Hand in Hand
Developers of conversational systems often get completely carried away by the engineering aspects of the development process, at the same time easily losing sight of how important data collection actually is for the whole process. Since we have seen too many chatbots fail exactly because of this reason, the conversational AI development cycle at PolyAI always runs hand in hand with data collection. Having this in mind, the following diagram presents how (what we call) the magic triangle of data collection contributes to different phases of our system development.
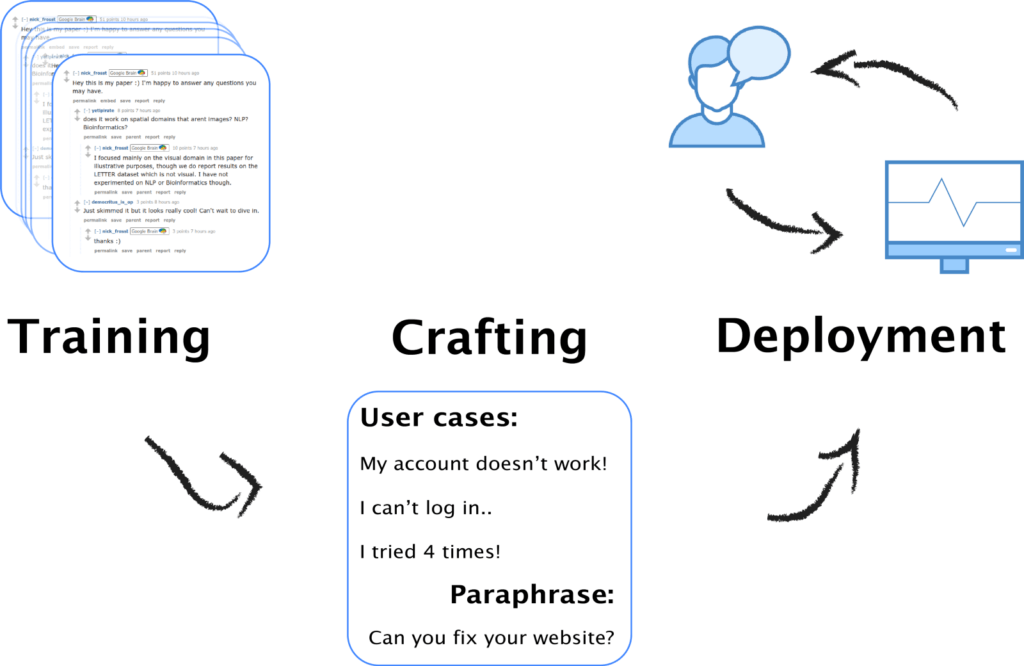
Training: During the training phase, we leverage billions of online discussion threads to foster our general-purpose conversational search engine. Since our conversational search engine doesn’t rely on any fine-grained semantic annotations but only textual information, it doesn’t require a carefully defined WOZ annotation framework to collect H2H interactions — in fact, any conversational data can be used to train our system. Moreover, this approach also eliminates the need for customizing data collection UI for each particular domain, which is not scalable in practice.
Crafting: Next, application-specific conversational agents are developed on top of the general-purpose conversational search engine. At this stage, the M2M paradigm comes in handy, as the chatbot developer can use a lot of help from the automatic paraphrase collection to increase the chatbot’s input and output coverage. Crowdworkers are then recruited to quickly bootstrap the data by either paraphrasing user questions or by providing appropriate answers given the dialogue context. This setup is easily parallelizable and allows us to gather a large amount of task-specialized data in a matter of hours.
Deployment: Finally, there is no better data than the actual interactions with end-users. Once the system is deployed, we step into the H2M phase where all dialogues and statistics are logged down. With more data, our conversational system continuously improves itself on its own to master the task it is designed for and to deliver better and better user experience over time.
The data-driven mindset — all hands on deck!
At PolyAI, we believe in machine learning, but we believe in data even more. In fact, this blog post is not about setting up a standard practice for data collection or choosing one paradigm over another, but rather about picking up and encouraging the data-driven mindset and its integration into daily practice and system development. At PolyAI, this is not only the principle on which we build our conversation agents, but also the core belief behind how the company was built — my colleagues at PolyAI are constantly improving our data collection platform, looking for better datasets available online, and trialling creative ways to collect dialogue data. What is more, this data-driven mindset also protects us from the temptation of getting hooked on handcrafted solutions and keeps our system infrastructure healthy and ready to learn from more data. After all, only a data-driven infrastructure can scale exponentially with the exponential growth of user data, this way bypassing the unscalable design based on convoluted handcrafted rules made by a handful of engineers.
Conclusion
Data plays a fundamental role in solving conversational AI at the industry scale. The ability to collect high-quality data efficiently for any use case is just as important as developing new machine learning models. By building effective data collection and powerful deep learning models in tandem, PolyAI aims to explore new technical frontiers and build conversational AI that truly makes a difference in our daily lives.
Thanks to Ivan Vulić and Tsung-Hsieng Wen for reading drafts of this.


